Guide to Uploading Own .txt Corpus Python Nltk
In this part of the series, nosotros're going to scrape the contents of a webpage and and then process the text to display word counts.
Updates:
- 02/10/2020: Upgraded to Python version iii.8.1 as well as the latest versions of requests, BeautifulSoup, and nltk. Encounter below for details.
- 03/22/2016: Upgraded to Python version three.five.1 as well as the latest versions of requests, BeautifulSoup, and nltk. Meet below for details.
- 02/22/2015: Added Python three support.
Recollect: Here'south what we're building - A Flask app that calculates word-frequency pairs based on the text from a given URL.
- Office One: Set upward a local development environment and then deploy both a staging and a product environment on Heroku.
- Part Ii: Prepare a PostgreSQL database along with SQLAlchemy and Alembic to handle migrations.
- Function 3: Add in the dorsum-end logic to scrape and so process the give-and-take counts from a webpage using the requests, BeautifulSoup, and Tongue Toolkit (NLTK) libraries. (current)
- Office Four: Implement a Redis task queue to handle the text processing.
- Part Five: Set up Athwart on the front end-end to continuously poll the back-end to see if the asking is done processing.
- Function Six: Button to the staging server on Heroku - setting upwards Redis and detailing how to run two processes (web and worker) on a single Dyno.
- Function Vii: Update the front end-end to make it more user-friendly.
- Function Eight: Create a custom Angular Directive to display a frequency distribution chart using JavaScript and D3.
Need the lawmaking? Take hold of it from the repo.
Install Requirements
Tools used:
- requests (2.22.0) - a library for sending HTTP requests
- BeautifulSoup (four.viii.2) - a tool used for scraping and parsing documents from the spider web
- Natural Language Toolkit (3.4.v) - a natural linguistic communication processing library
Navigate into the project directory to activate the virtual environment, via autoenv, and then install the requirements:
$ cd flask-by-example $ python -m pip install requests == 2.22.0 beautifulsoup4 == 4.8.ii nltk == 3.4.5 $ python -m pip freeze > requirements.txt Refactor the Index Route
To get started, let's get rid of the "hello earth" office of the alphabetize route in our app.py file and set upwardly the route to return a form to accept URLs. First, add a templates folder to agree our templates and add an index.html file to information technology.
$ mkdir templates $ bear on templates/alphabetize.html Prepare a very basic HTML page:
<!DOCTYPE html> < html > < caput > < title >Wordcount</ championship > < meta proper noun = "viewport" content = "width=device-width, initial-scale=ane.0" > < link href = "//netdna.bootstrapcdn.com/bootstrap/three.3.6/css/bootstrap.min.css" rel = "stylesheet" media = "screen" > < fashion > . container { max-width : k px ; } </ mode > </ caput > < body > < div form = "container" > < h1 >Wordcount 3000</ h1 > < form role = "grade" method = 'Mail service' activeness = '/' > < div class = "form-grouping" > < input type = "text" name = "url" class = "form-control" id = "url-box" placeholder = "Enter URL..." fashion = "max-width: 300px;" autofocus required > </ div > < button type = "submit" course = "btn btn-default" >Submit</ push button > </ grade > < br > {% for mistake in errors %} < h4 >{{ mistake }}</ h4 > {% endfor %} </ div > < script src = "//lawmaking.jquery.com/jquery-2.ii.one.min.js" ></ script > < script src = "//netdna.bootstrapcdn.com/bootstrap/3.iii.6/js/bootstrap.min.js" ></ script > </ trunk > </ html > We used Bootstrap to add a chip of style so our page isn't completely hideous. And then we added a form with a text input box for users to enter a URL into. Additionally, we utilized a Jinja for loop to iterate through a list of errors, displaying each one.
Update app.py to serve the template:
import os from flask import Flask , render_template from flask_sqlalchemy import SQLAlchemy app = Flask ( __name__ ) app . config . from_object ( os . environ [ 'APP_SETTINGS' ]) app . config [ 'SQLALCHEMY_TRACK_MODIFICATIONS' ] = False db = SQLAlchemy ( app ) from models import Effect @app . road ( '/' , methods = [ 'Become' , 'Mail service' ]) def index (): return render_template ( 'index.html' ) if __name__ == '__main__' : app . run () Why both HTTP methods, methods=['GET', 'Mail service']? Well, we will somewhen use that same route for both Get and POST requests - to serve the alphabetize.html page and handle form submissions, respectively.
Fire upwards the app to test it out:
$ python manage.py runserver Navigate to http://localhost:5000/ and y'all should see the form staring back at you.
Requests
At present allow'southward utilise the requests library to grab the HTML page from the submitted URL.
Change your index route like and so:
@app . route ( '/' , methods = [ 'GET' , 'POST' ]) def index (): errors = [] results = {} if request . method == "POST" : # get url that the user has entered try : url = request . class [ 'url' ] r = requests . go ( url ) print ( r . text ) except : errors . append ( "Unable to get URL. Delight brand sure it's valid and try again." ) return render_template ( 'index.html' , errors = errors , results = results ) Make sure to update the imports every bit well:
import os import requests from flask import Flask , render_template , asking from flask_sqlalchemy import SQLAlchemy - Here, nosotros imported the
requestslibrary besides as therequestobject from Flask. The one-time is used to transport external HTTP Get requests to grab the specific user-provided URL, while the latter is used to handle GET and POST requests within the Flask app. - Next, nosotros added variables to capture both errors and results, which are passed into the template.
-
Within the view itself, nosotros checked if the request is a Become or Postal service-
- If Mail: We grabbed the value (URL) from the course and assigned information technology to the
urlvariable. Then we added an exception to handle any errors and, if necessary, appended a generic error bulletin to theerrorslisting. Finally, we rendered the template, including theerrorslist andresultsdictionary. - If Become: We simply rendered the template.
- If Mail: We grabbed the value (URL) from the course and assigned information technology to the
Let's exam this out:
$ python manage.py runserver You should exist able to blazon in a valid webpage and in the concluding you'll come across the text of that page returned.
Note: Make certain, that your URL includes
http://orhttps://. Otherwise our application won't notice, that it'southward a valid URL.
Text Processing
With the HTML in hand, let's at present count the frequency of the words that are on the folio and display them to the end user. Update your code in app.py to the post-obit and we'll walk through what's happening:
import bone import requests import operator import re import nltk from flask import Flask , render_template , request from flask_sqlalchemy import SQLAlchemy from stop_words import stops from collections import Counter from bs4 import BeautifulSoup app = Flask ( __name__ ) app . config . from_object ( os . environ [ 'APP_SETTINGS' ]) app . config [ 'SQLALCHEMY_TRACK_MODIFICATIONS' ] = True db = SQLAlchemy ( app ) from models import Result @app . route ( '/' , methods = [ 'Get' , 'Post' ]) def index (): errors = [] results = {} if asking . method == "POST" : # get url that the person has entered try : url = request . form [ 'url' ] r = requests . go ( url ) except : errors . append ( "Unable to become URL. Please make sure it's valid and attempt once more." ) render render_template ( 'index.html' , errors = errors ) if r : # text processing raw = BeautifulSoup ( r . text , 'html.parser' ) . get_text () nltk . data . path . suspend ( './nltk_data/' ) # gear up the path tokens = nltk . word_tokenize ( raw ) text = nltk . Text ( tokens ) # remove punctuation, count raw words nonPunct = re . compile ( '.*[A-Za-z].*' ) raw_words = [ w for w in text if nonPunct . match ( westward )] raw_word_count = Counter ( raw_words ) # finish words no_stop_words = [ westward for w in raw_words if w . lower () not in stops ] no_stop_words_count = Counter ( no_stop_words ) # salve the results results = sorted ( no_stop_words_count . items (), key = operator . itemgetter ( one ), reverse = True ) try : consequence = Result ( url = url , result_all = raw_word_count , result_no_stop_words = no_stop_words_count ) db . session . add ( result ) db . session . commit () except : errors . append ( "Unable to add particular to database." ) return render_template ( 'index.html' , errors = errors , results = results ) if __name__ == '__main__' : app . run () Create a new file chosen stop_words.py and add together the post-obit list:
stops = [ 'i' , 'me' , 'my' , 'myself' , 'we' , 'our' , 'ours' , 'ourselves' , 'you' , 'your' , 'yours' , 'yourself' , 'yourselves' , 'he' , 'him' , 'his' , 'himself' , 'she' , 'her' , 'hers' , 'herself' , 'information technology' , 'its' , 'itself' , 'they' , 'them' , 'their' , 'theirs' , 'themselves' , 'what' , 'which' , 'who' , 'whom' , 'this' , 'that' , 'these' , 'those' , 'am' , 'is' , 'are' , 'was' , 'were' , 'exist' , 'been' , 'being' , 'have' , 'has' , 'had' , 'having' , 'do' , 'does' , 'did' , 'doing' , 'a' , 'an' , 'the' , 'and' , 'just' , 'if' , 'or' , 'because' , 'as' , 'until' , 'while' , 'of' , 'at' , 'by' , 'for' , 'with' , 'near' , 'against' , 'between' , 'into' , 'through' , 'during' , 'before' , 'afterward' , 'above' , 'beneath' , 'to' , 'from' , 'up' , 'downwards' , 'in' , 'out' , 'on' , 'off' , 'over' , 'under' , 'again' , 'farther' , 'then' , 'once' , 'here' , 'there' , 'when' , 'where' , 'why' , 'how' , 'all' , 'whatsoever' , 'both' , 'each' , 'few' , 'more' , 'most' , 'other' , 'some' , 'such' , 'no' , 'nor' , 'not' , 'simply' , 'own' , 'same' , 'so' , 'than' , 'too' , 'very' , 'due south' , 't' , 'can' , 'will' , 'just' , 'don' , 'should' , 'now' , 'id' , 'var' , 'office' , 'js' , 'd' , 'script' , ' \' script' , 'fjs' , 'document' , 'r' , 'b' , 'g' , 'due east' , ' \' s' , 'c' , 'f' , 'h' , 'l' , 'k' ] What's happening?
Text Processing
-
In our index road we used beautifulsoup to clean the text, by removing the HTML tags, that we got back from the URL every bit well as nltk to-
- Tokenize the raw text (interruption upwardly the text into individual words), and
- Plow the tokens into an nltk text object.
-
In order for nltk to piece of work properly, you need to download the correct tokenizers. First, create a new directory -
mkdir nltk_data- and so run -python -1000 nltk.downloader.When the installation window appears, update the 'Download Directory' to whatever_the_absolute_path_to_your_app_is/nltk_data/.
Then click the 'Models' tab and select 'punkt' nether the 'Identifier' column. Click 'Download'. Check the official documentation for more information.
Remove Punctuation, Count Raw Words
- Since we don't want punctuation counted in the last results, nosotros created a regular expression that matched annihilation non in the standard alphabet.
- Then, using a listing comprehension, we created a list of words without punctuation or numbers.
- Finally, nosotros tallied the number of times each word appeared in the list using Counter.
Cease Words
Our current output contains a lot of words that we probable don't want to count - i.due east., "I", "me", "the", and so forth. These are chosen cease words.
- With the
stopslisting, we once more used a listing comprehension to create a final list of words that practise non include those stop words. - Next, we created a dictionary with the words (as keys) and their associated counts (as values).
- And finally we used the sorted method to go a sorted representation of our dictionary. Now we can utilise the sorted information to display the words with the highest count at the height of the listing, which means that we won't have to practise that sorting in our Jinja template.
For a more than robust terminate word listing, employ the NLTK stopwords corpus.
Save the Results
Finally, we used a endeavor/except to save the results of our search and the subsequent counts to the database.
Display Results
Allow's update index.html in order to display the results:
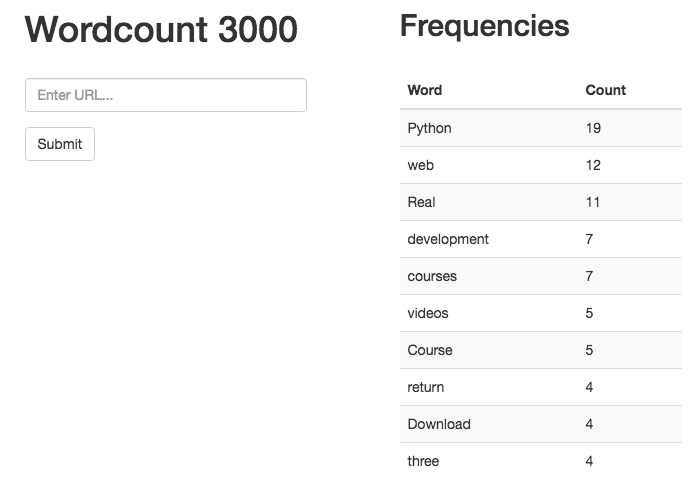
<!DOCTYPE html> < html > < caput > < championship >Wordcount</ title > < meta name = "viewport" content = "width=device-width, initial-calibration=one.0" > < link href = "//netdna.bootstrapcdn.com/bootstrap/three.1.1/css/bootstrap.min.css" rel = "stylesheet" media = "screen" > < style > . container { max-width : m px ; } </ fashion > </ caput > < body > < div grade = "container" > < div class = "row" > < div class = "col-sm-five col-sm-offset-1" > < h1 >Wordcount 3000</ h1 > < br > < form part = "form" method = "Mail service" action = "/" > < div form = "form-group" > < input blazon = "text" proper name = "url" class = "form-control" id = "url-box" placeholder = "Enter URL..." style = "max-width: 300px;" > </ div > < button blazon = "submit" grade = "btn btn-default" >Submit</ push button > </ form > < br > {% for error in errors %} < h4 >{{ mistake }}</ h4 > {% endfor %} < br > </ div > < div class = "col-sm-5 col-sm-outset-i" > {% if results %} < h2 >Frequencies</ h2 > < br > < div id = "results" > < tabular array class = "table table-striped" manner = "max-width: 300px;" > < thead > < tr > < thursday >Discussion</ th > < thursday >Count</ th > </ tr > </ thead > {% for result in results%} < tr > < td >{{ upshot[0] }}</ td > < td >{{ outcome[one] }}</ td > </ tr > {% endfor %} </ tabular array > </ div > {% endif %} </ div > </ div > </ div > < br >< br > < script src = "//code.jquery.com/jquery-ane.11.0.min.js" ></ script > < script src = "//netdna.bootstrapcdn.com/bootstrap/3.1.1/js/bootstrap.min.js" ></ script > </ body > </ html > Here, we added an if argument to run across if our results dictionary has anything in it and then added a for loop to iterate over the results and display them in a table. Run your app and you lot should exist able to enter a URL and get back the count of the words on the page.
$ python manage.py runserver What if we wanted to brandish only the first ten keywords?
results = sorted ( no_stop_words_count . items (), key = operator . itemgetter ( 1 ), contrary = True )[: 10 ] Examination information technology out.
Summary
Okay great. Given a URL nosotros tin can count the words that are on the page. If you utilize a site without a massive amount of words, like https://realpython.com, the processing should happen fairly quickly. What happens if the site has a lot of words, though? For example, effort out https://gutenberg.ca. You'll notice that this takes longer to procedure.
If you have a number of users all hitting your site at once to go word counts, and some of them are trying to count larger pages, this can go a problem. Or perhaps y'all decide to change the functionality so that when a user inputs a URL, we recursively scrape the entire web site and calculate word frequencies based on each individual page. With enough traffic, this will significantly irksome downward the site.
What's the solution?
Instead of counting the words later on each user makes a asking, we need to use a queue to procedure this in the backend - which is exactly where volition starting time next time in Part 4.
For now, commit your lawmaking, but before yous push button to Heroku, y'all should remove all language tokenizers except for English forth with the zip file. This will significantly reduce the size of the commit. Keep in listen though that if you practice process a not-English language site, information technology volition only process English words.
└── nltk_data └── tokenizers └── punkt ├── PY3 │ └── english.pickle └── english.pickle Button it upwardly to the staging surround only since this new text processing characteristic is only half finished:
Test it out on staging. Comment if you take questions. Run across you next time!
This is a collaboration piece betwixt Cam Linke, co-founder of Startup Edmonton, and the folks at Real Python
Source: https://realpython.com/flask-by-example-part-3-text-processing-with-requests-beautifulsoup-nltk/
0 Response to "Guide to Uploading Own .txt Corpus Python Nltk"
Post a Comment